
From Prompt to Prod: Sicuranext Evaluates AI Integration in SOC Analysis
At Sicuranext, we do not evaluate AI with artificial examples. We replay realistic SOC workflows, measure correctness and consistency, verify tool behavior, and put guardrails around automation before it touches our SOC.
AI in a SOC should not be judged by whether it can produce a convincing paragraph. It should be judged by whether it behaves correctly inside a real workflow: on noisy alerts, incomplete evidence, repeated executions, structured outputs, tool calls, and operational guardrails. A beautifully phrased mistake is still a mistake. In security operations, it can also be an expensive one.
That is why I approached LLM adoption as an engineering problem before treating it as a product feature. If AI is going to help in SOC triage and analysis, it has to earn trust the same way any serious component does: with testing, telemetry, thresholds, and rollback discipline.
Disclaimer
Just a quick heads-up! While we’re diving deep into how we evaluate the intelligence and logic of our AI integrations, this post doesn't cover the heavy-duty security guardrails we have in place. Rest assured, we apply rigorous filtering, prompt injection protection, and data sanitization layers to keep the system locked down. We're just focusing on the "brain" and its performance for today!
SOC AI Evaluation Starts at the Workflow Level
The first mistake teams make with LLMs in security is evaluating the model as if it were a chatbot. A SOC workflow is not a chat. It is an execution path.
An alert pops up, gets normalized, enriched, compared with historical patterns, optionally escalated to artifact retrieval, and only then turned into a structured verdict and possibly an analyst-attention-requiring note or a silenced false positive (hopefully). That means the real unit under test is not the prompt alone. It is the workflow: data in, context assembly, tool boundaries, output schema, safe routing, and operational side effects.
This is also where evaluation becomes honest. The question is no longer “does the answer sound reasonable?” The question becomes “did the workflow behave correctly under realistic conditions?” That is a much less glamorous question, and a much more useful one.

What I measure
In practice, I score our AI-assisted SOC workflow across four dimensions:
Truthfulness: does the model converge to the analyst-reviewed answer?Determinism: does the same alert produce stable outcomes across repeated runs?Tool discipline: does the agent retrieve extra evidence when it is actually needed?Operational reliability: does the whole pipeline stay valid, parseable, and robust across model and prompt profiles?
For simplicity, the math below focuses on a single output field: risk_level. In practice, the tests cover additional outputs, but risk_level is the clearest lens for explaining the methodology without turning this blog post into a research paper.
1. Truthfulness: are we converging to the right analysis?
Truthfulness is the part that requires a human-reviewed dataset. There is no shortcut around that. If you want to know whether the model is correct, you need something to compare it against.
For each alert a, I replay the workflow R times and compare the observed risk level against the expected analyst-reviewed risk level.
I map the ordinal risk levels to integers:
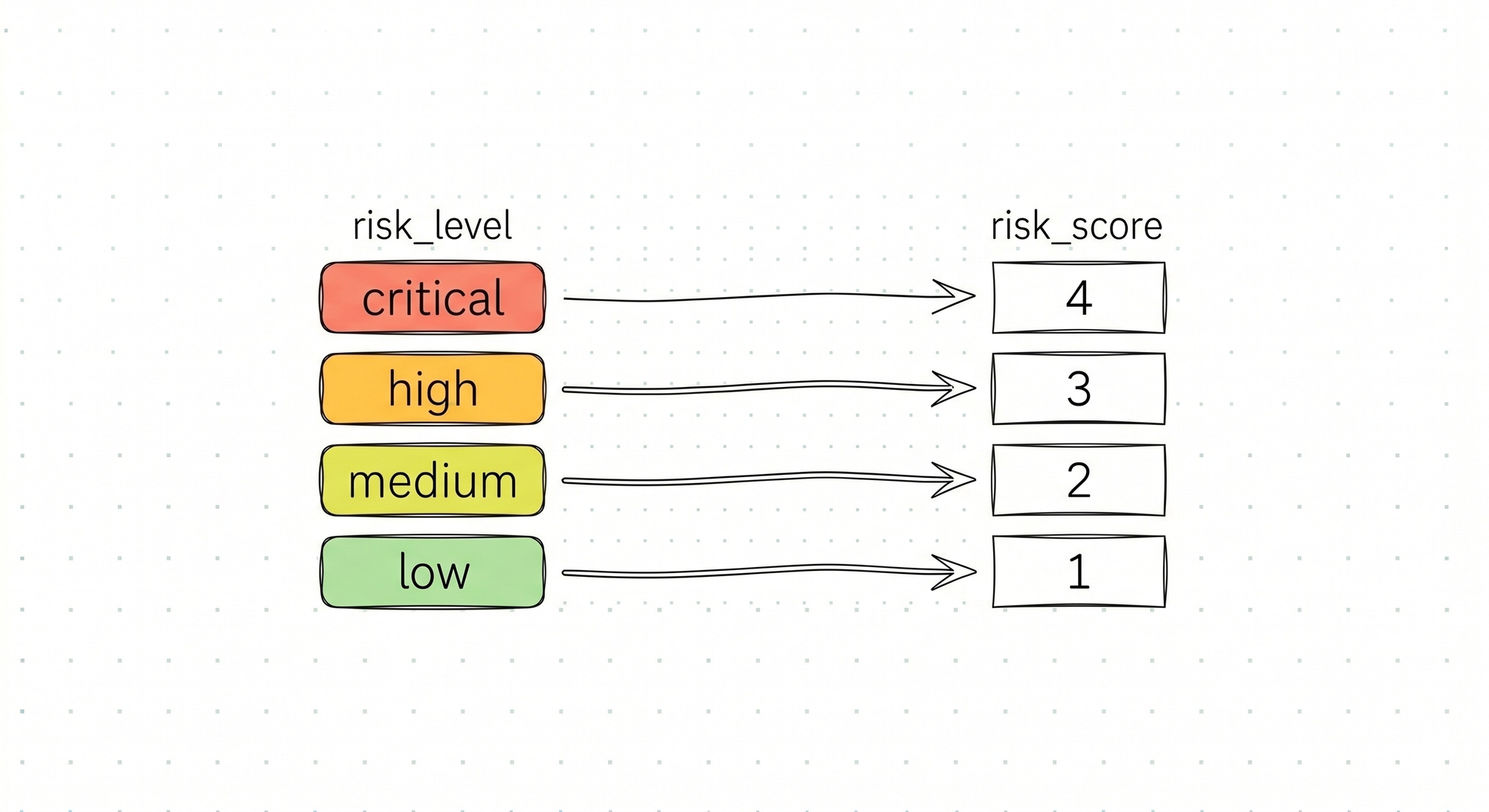
Because a score like
67/100 can suggest a level of precision the model does not really have. For LLMs, a safer output is usually a bounded category such as Low / Medium / High / Critical, which can then be mapped deterministically to an internal score range. Empirical work on LLM calibration has shown that numeric confidence can be unreliable, so asking for a number may add false precision rather than real rigor. For automation, verbal categories are usually easier to constrain, test, and compare across runs.That lets us compute not only exact matches, but also distance from the correct answer. A model that predicts low instead of medium is wrong, but it is less wrong than predicting low instead of critical.
The three truthfulness metrics I like most are:Alert-level exact match: The modal risk level across repeated runs for an alert must match its expected risk level.Run-level exact match: Each individual run is checked against the expected risk level.Mean risk error: The average absolute distance between observed and expected risk level.
A publication-safe version of that logic looks like this:
RISK_TO_INT = {"low": 1, "medium": 2, "high": 3, "critical": 4}
def risk_level_error(observed: str, expected: str) -> int:
return abs(RISK_TO_INT[observed] - RISK_TO_INT[expected])
def modal_value(values: list[str]) -> str | None:
return max(values, key=values.count) if values else None
modal_risk = modal_value(observed_risks_for_alert)
alert_pass = modal_risk == expected_risk
run_exact_rate = sum(r == expected_risk for r in observed_risks_for_alert) / len(observed_risks_for_alert)
mean_risk_error = sum(risk_level_error(r, expected_risk) for r in observed_risks_for_alert) / len(observed_risks_for_alert)
Why take into consideration all three? Because they answer different questions.
Alert-level exact matchtells us whether the workflow converges to the right operational conclusion for a case. (thus giving the possibility to detect specific patterns of cases where success rate was low, and take actions for improvement)Run-level exact matchtells us how often the workflow is individually right. (if you get a 100% success here over a large test sample, just be sure that your system has a direct connection to God)Mean risk errortells us how wrong it is when it misses. In risk assessment terms, that matters. A one-step miss is not the same thing as falling off a cliff.
For a public production-grade benchmark posture, a reasonable target band might be:
alert-level risk success >= 85%run-level risk success >= 80%mean risk error <= 0.35
Those are not a dump of our private gates. They are the kind of target bands I believe are aligned with serious evaluation practice in modern AI and security engineering.
2. Determinism: is the system stable, or is each run a fresh creative interpretation of reality?
Truthfulness asks whether the answer is correct. Determinism asks whether the answer is consistent. That sounds similar, but it is not the same test at all.
For determinism, I do not compare against human truth. I compare repeated runs against each other. This means determinism can be measured without a labeled dataset in the strict sense. You still need representative alerts to replay, but the metric itself does not require human annotation.
The first determinism metric is per-alert consistency:
consistency(a) = average( observed_risk(a,r) == modal_risk(a) )
If five replays returncritical, critical, critical, high, critical, consistency is4/5 = 80%.
But if they returncritical, critical, critical, low, criticalalso the consistency is4/5 = 80%.
So both cases look equally stable under consistency, even though the second one clearly has a much larger swing (and might give me cold sweats). That is why I need a second metric.
The second metric is more informative for ordinal labels: standard deviation (σ).
Instead of asking “how different have we behaved?”, I ask “how spread our behaviors were?” Once the level is mapped to a score, I can compute the standard deviation of repeated outputs:
sigma(a) = sqrt( average( (risk(a,r) - mean_risk(a))^2 ) )
For critical, critical, critical, high, critical, the mapped scores are 4, 4, 4, 3, 4: the mean is 3.8, and the standard deviation (σ) is 0.4.
For critical, critical, critical, low, critical, the mapped scores are 4, 4, 4, 1, 4: the mean is 3.4, and the standard deviation (σ) is 1.2. I think you got the point.

That logic looks like this:
RISK_TO_INT = {"low": 1, "medium": 2, "high": 3, "critical": 4}
def consistency_rate(values: list[str]) -> float:
modal = max(values, key=values.count)
return sum(v == modal for v in values) / len(values)
def risk_level_stddev(values: list[str]) -> float:
xs = [RISK_TO_INT[v] for v in values]
mean = sum(xs) / len(xs)
variance = sum((x - mean) ** 2 for x in xs) / len(xs)
return variance ** 0.5
This is why determinism is not a substitute for truthfulness. A model can produce the same wrong answer five times in a row and look wonderfully stable while still failing the operational goal.
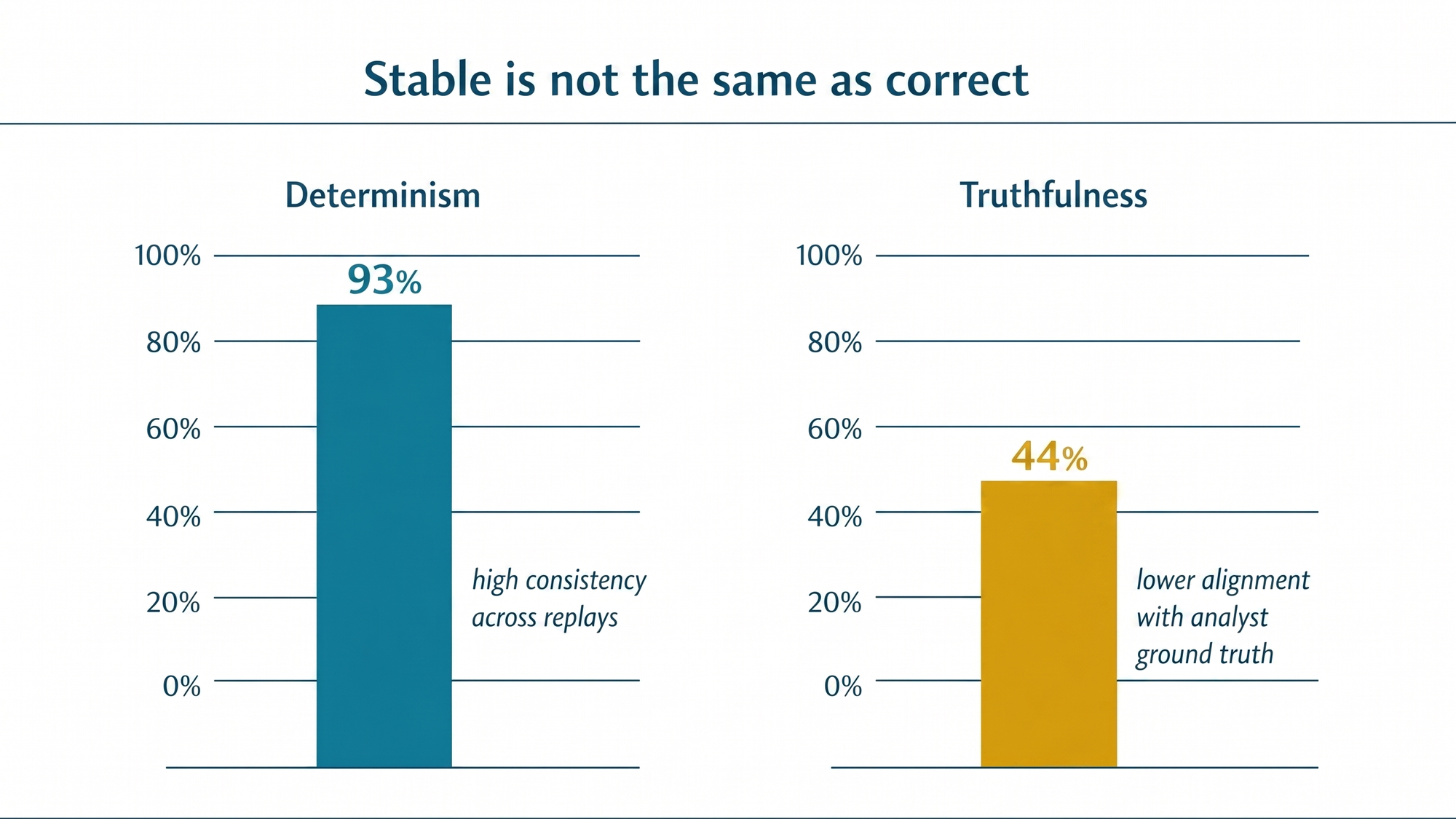
On determinism, the bands I like are:
risk consistency >= 90%tool consistency >= 95%risk-level standard deviation <= 0.20
If truthfulness tells you whether the model knows the answer, determinism tells you whether it changes its mind too easily.
3. Tool discipline: does the agent know when NOT to guess?
This is the part many AI evaluations quietly ignore.
Many alerts cannot be judged from the original event alone. They need one more piece of evidence: a retrieved script, a configuration file, an archive, chain of process, network logs, or another artifact from the endpoint. In those cases, the correct behavior is not “answer faster.” The correct behavior is “fetch the missing context.”
That means tool use is not a fancy feature. It is part of the decision.
In the evaluation dataset, some alerts are labeled as requiring artifact retrieval before the model can reasonably settle on a risk level. For those alerts, I track whether the workflow actually invoked the retrieval tool. At that point the question is no longer linguistic. It is binary:
expected_tool = true/falseobserved_tool = true/false
From there, the simplest and most useful metric is obligation recall:
tool_obligation_recall = retrieved_when_required / total_required_cases
But I'd also care about the opposite failure mode:
unnecessary_retrieval_rate = retrieved_when_not_required / total_non_required_cases
Why both? Because a good SOC agent should not bluff when it lacks evidence, but it also should not panic-download half the endpoint every time it sees a slightly weird process tree. Better to fetch than bluff, but still better to fetch with discipline.
A simplified version of the retrieval tool looks like this:
def get_file_from_endpoint(kibana, max_size_bytes=10 * 1024 * 1024):
async def tool(agent_id: str, file_path: str):
action_id = await kibana.execute_action_get_file(agent_id=agent_id, file_path=file_path)
result = await kibana.wait_for_file(agent_id=agent_id, action_id=action_id)
if result.size > max_size_bytes:
return {"action_status": "error", "error": "file too large"}
return {
"action_status": "success",
"contents": [{"file_name": result.name, "file_content": result.text_content}],
}
return Tool(
tool,
name="get_file_from_endpoint",
description="Download a file from endpoint if further investigation requires file analysis.",
strict=True,
)
That single control point does two important things. It gives the workflow evidence it would otherwise miss, and it gives the engineering team something measurable instead of hand-wavy “agentic behavior.”
For tool discipline, the thresholds worth showing are:
mandatory tool recall >= 95%unnecessary retrieval rate <= 5%
In a SOC, the right tool call is often the difference between “this looks odd” and “this is just a driver update acting like a driver update.”
4. Operational reliability: can the workflow survive production reality?
Operational reliability is where nice demos go to die.
A production workflow has deterministic parts around the LLM that must behave perfectly every time: alert loading, exclusion lists, supported event-module checks, dataset assembly, schema validation, tool wrappers, timeouts, retries, export paths, and downstream observability. If those parts are flaky, the model never even gets the chance to fail interestingly.
This is where classical engineering discipline still does most of the heavy lifting.
In our case, pytest validates the deterministic envelope around the LLM: that the expected dataset is assembled correctly, that unsupported alerts are skipped correctly, that exclusions are respected, that similarity gating behaves as designed, and that orchestration logic does not violate action or routing boundaries.
A small example from that style of testing is checking that the exact dataset mounted for the model matches the expected one:
async def test_expected_user_prompt_from_dataset(
self,
alert_id: str,
) -> None:
expected_dataset = self._load_dataset(alert_id)
_set_ai_response(self.ai_agent_mock)
from wall_e.analysis.tasks import AnalysisRunParams
result = await self.analysis.run(AnalysisRunParams(alert_id=alert_id))
assert result.status == AnalysisStatusEnum.success
assert result.message == "Alert analysis completed"
assert result.analysis is not None
assert result.ai_model == self.ai_agent_mock.model.model_name
def check_user_prompt(user_prompt: str) -> bool:
dataset = json.loads(user_prompt)
diff = deepdiff.DeepDiff(expected_dataset.expected_dataset, dataset, ignore_order=True)
assert diff == {}
return True
self.ai_agent_mock.assert_run(check_kwargs={"user_prompt": check_user_prompt})This is not glamorous, but it is the sort of test that keeps AI systems honest. If the model sees the wrong context, your prompt tuning is already downstream of the real bug.
Structured output control matters too. I use pydantic_ai because controlled workflows need a strongly typed contract between model output and automation logic. Different model families may require different output strategies, but the point is the same: free-form prose should not be allowed to drift directly into operational actions.
A simplified version of that provider-aware output control looks like this:
if is_gemini_model(model_name):
return ToolOutput(AnalysisResponse, name="analysis_response")
return NativeOutput([AnalysisResponse], name="analysis_response")
That may look like a small implementation detail. It is not. It is part of operational reliability. Different providers and model families can fail in different ways, and production-grade evaluation has to catch compatibility failures, schema failures, and runtime failures, not just semantic ones.
This is also the right place to compare multiple prompt and model profiles. The best profile for truthfulness is not always the best for determinism. The best profile for tool discipline may not be the best for latency or schema compliance. That is why model selection should be treated as a measured engineering tradeoff, not a taste preference.
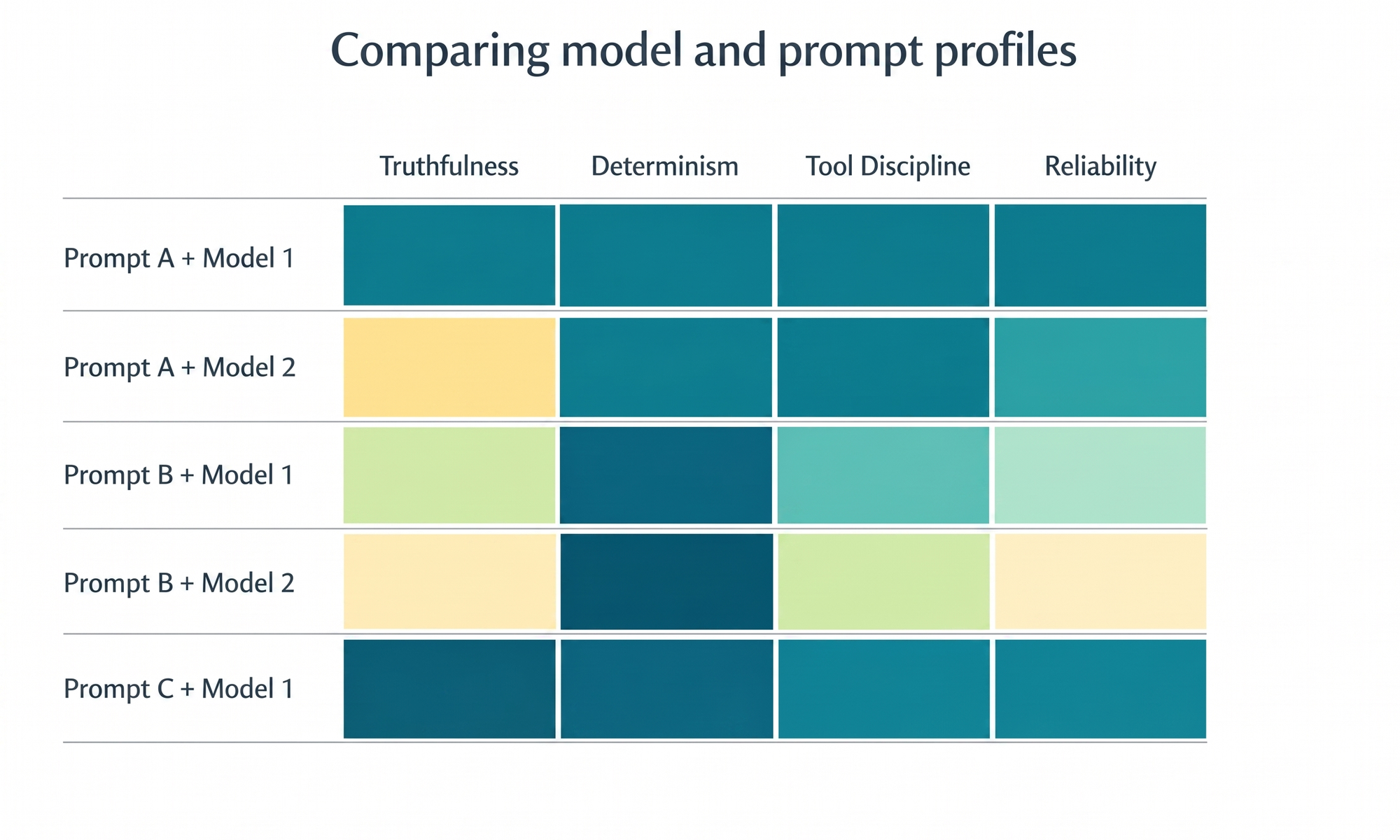
For operational reliability, this is the kind of band worth aiming for:
structured-output validity >= 99%workflow runtime success >= 99.5%tool execution success >= 99%provider/profile compatibility explicitly trackedprompt-profile regression monitoring on every meaningful change
At this point, the system stops being “an LLM experiment” and starts behaving like software.
A concrete example from the dataset
To make this less abstract, here is one real case pattern from the evaluation corpus, lightly sanitized for publication.
The alert was triggered by the rule Unusual Parent Process for cmd.exe. At first glance, the process chain looks awkward enough to deserve attention:
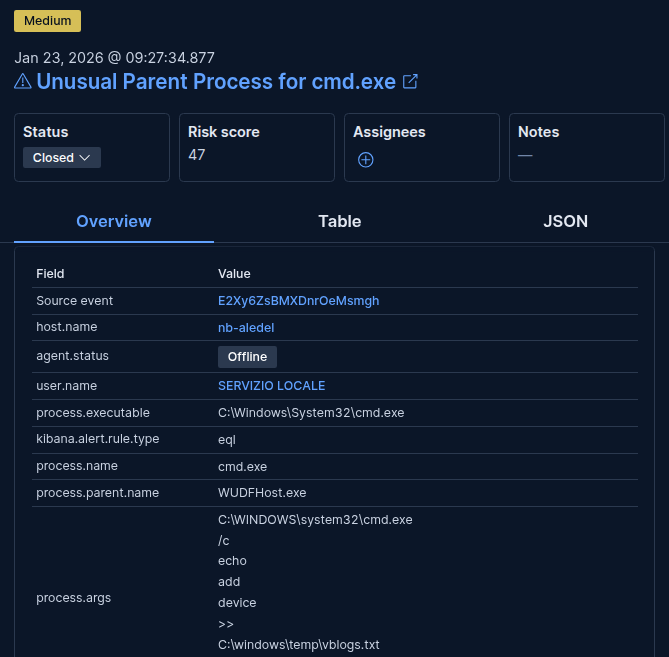
That is not the kind of process tree a SOC analyst wants to rubber-stamp without context. So this is exactly the kind of case where tool discipline matters.
The human-reviewed analysis for the same alert concluded Low risk, but only after retrieving and reading the file vblogs.txt:
Process spawned by WUDFHost.exe, legit, with no suspicious flags.
Analyzed file vblogs.txt that contains this bit:
START /b /separate
C:\WINDOWS\System32\DriverStore\FileRepository\vb1.inf_amd64_e36c1e9e0f5add7b\updater.exe
C:\WINDOWS\System32\DriverStore\FileRepository\vb1.inf_amd64_e36c1e9e0f5add7b\firmware.swu
1.0.3_d9d3c0a
updater.exe is signed by Bose Corporation.
Result: Bose hardware device using user drivers.
And the retrieved file itself contains the clue that changes the confidence of the verdict:
create driver
add device
START /b /separate C:\WINDOWS\System32\DriverStore\FileRepository\vb1.inf_amd64_e36c1e9e0f5add7b\updater.exe C:\WINDOWS\System32\DriverStore\FileRepository\vb1.inf_amd64_e36c1e9e0f5add7b\firmware.swu 1.0.3_d9d3c0a
updater-exit-code_2 ...
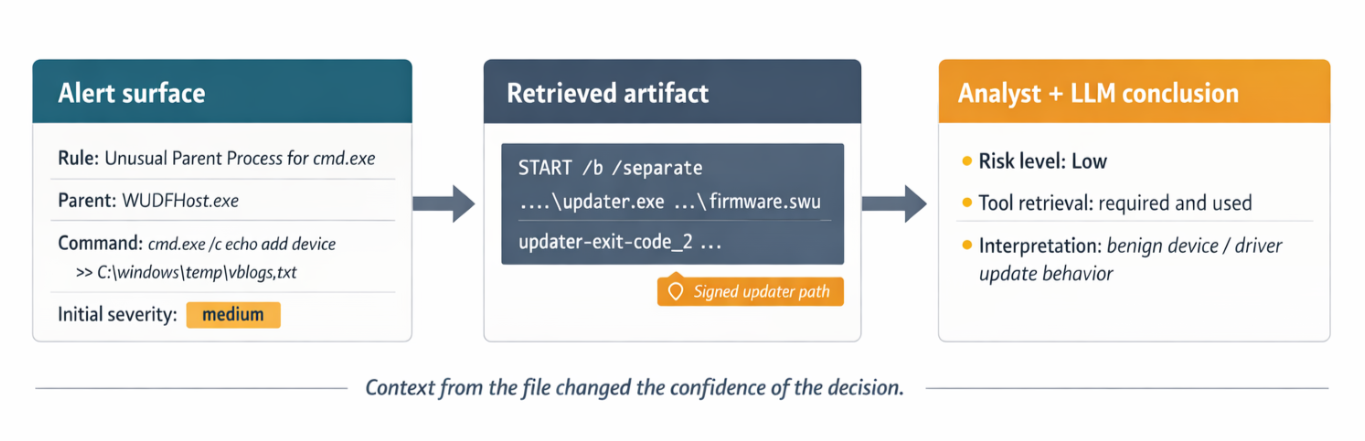
Without the file, the workflow sees a suspicious parent-child relationship and a temp-file write. With the file, the workflow sees a much more credible explanation: driver and firmware update behavior associated with a signed vendor updater.
Here's the kind of confidence shift that makes tool use valuable. The extra artifact does not just add more text. It changes the investigation from “suspicious shell behavior” to “benign hardware maintenance pattern.”
In one successful evaluation profile, the workflow handled this case cleanly across all 4 replays:
15:58:25,038 [INFO] Running analysis for alert=2fca61d939159c8e6f78b13fc6f67a95c64c782640148b45ea5fc13d99e00dc4 repetition=4/10
15:58:41,113 [INFO] Shipped llm_test run result to elastic: run_id=llm-test-run-6e226919269c41b5ba72d878ec1aceb8-4
15:58:41,113 [INFO] Completed analysis: expected_risk=low, observed_risk=low, expected_tool=True, observed_tool=True
15:58:41,113 [INFO] Running analysis for alert=2fca61d939159c8e6f78b13fc6f67a95c64c782640148b45ea5fc13d99e00dc4 repetition=5/10
15:58:54,135 [INFO] Shipped llm_test run result to elastic: run_id=llm-test-run-6e226919269c41b5ba72d878ec1aceb8-5
15:58:54,136 [INFO] Completed analysis: expected_risk=low, observed_risk=low, expected_tool=True, observed_tool=True
15:58:54,136 [INFO] Running analysis for alert=2fca61d939159c8e6f78b13fc6f67a95c64c782640148b45ea5fc13d99e00dc4 repetition=6/10
15:59:11,062 [INFO] Shipped llm_test run result to elastic: run_id=llm-test-run-6e226919269c41b5ba72d878ec1aceb8-6
15:59:11,062 [INFO] Completed analysis: expected_risk=low, observed_risk=low, expected_tool=True, observed_tool=True
15:59:11,063 [INFO] Running analysis for alert=2fca61d939159c8e6f78b13fc6f67a95c64c782640148b45ea5fc13d99e00dc4 repetition=7/10
15:59:25,296 [INFO] Shipped llm_test run result to elastic: run_id=llm-test-run-6e226919269c41b5ba72d878ec1aceb8-7
15:59:25,296 [INFO] Completed analysis: expected_risk=low, observed_risk=low, expected_tool=True, observed_tool=TrueThat's an example I care about because it proves two things at once:
- the workflow did not overreact to a suspicious-looking surface pattern
- the workflow knew it needed one more piece of evidence before settling on the answer
From engineering signal to business value
All of this may sound deeply technical, but the payoff is not just technical.
A workflow like this makes model changes safer, and it creates a cleaner separation between “this model sounds impressive” and “our workflow with this config profile is actually safe to trust.”
That has direct business value.
It reduces triage noise by catching regressions before they hit the analyst queue, and improves rollout confidence because every model or prompt change ships with a measurable delta instead of vibes. It saves the dev team from the maintenance burden of debugging silent drift, lowers the cost of switching providers or prompt profiles because the comparison is already instrumented, and gives customers a more credible story around secure AI adoption than a vendor demo can. Most of all, it keeps the SOC from becoming a live beta program for unmeasured automation.
And it is much cheaper to disappoint a dashboard than a SOC analyst at 2 a.m. (I've been in their shoes, and my thoughts are with them)
Evaluation is not overhead. In AI-enabled security operations, evaluation is part of the product.
AI integration should not be treated as a magic layer dropped on top of a workflow. I treat it as a component that must be observed, tested, constrained, and earned.
That is why our evaluation philosophy starts from the workflow, not from the demo. Because in a SOC, the question is never whether the model can say something clever, but whether the workflow can reach the right conclusion consistently, retrieve missing evidence when needed, stay inside operational guardrails, and remain reliable when the cost of being wrong is real.