
Building Octofence WAAP Cache System & CDN: Lessons Learned and Best Practices

Caching is a critical component of any modern application, enabling fast and efficient delivery of content and data to users. However, finding the right caching solution can be a challenge, particularly when existing off-the-shelf solutions don’t meet your specific needs.
In this article, we’ll share our experience of building our own custom cache system and Content Delivery Network based on AWS from scratch. We’ll discuss the reasons why we decided to go down this route, the challenges we faced along the way, and the lessons we learned.
TL;DR: While building our custom cache system, everything that could go wrong did go wrong. Anyone said standards? Anyone said RFC? We learned a lot…
Why?
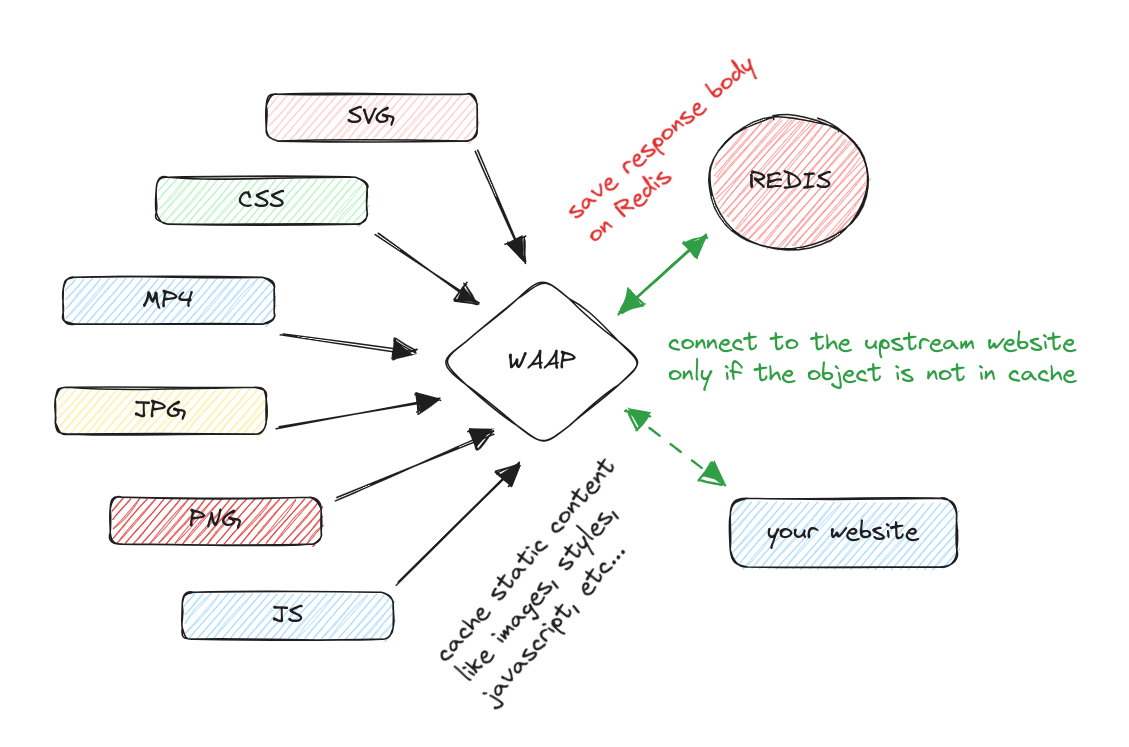
Caching static content has a lot of pros in terms of performance. But the most relevant advantage is to lower the network traffic costs. Our Octofence WAAP service is based on AWS, and every time our nodes connect to an upstream customer server we pay for outgoing traffic and NAT gateway usage. It could seem not a big deal, but if you think of hundreds of millions of HTTP requests per day it quickly becomes a lot of money at the end of the year.
Indeed, when users access resources via our AWS load balancers, they generate network traffic that is charged based on the amount of data transferred out of the AWS network. This can result in high costs, especially if the resources are accessed frequently or by many users. By using a proxy cache, requests for frequently accessed resources can be served directly from the cache without needing to be forwarded to the origin server. This reduces the amount of outgoing network traffic and can significantly lower costs associated with data transfer fees.
So, every time we reply from our cache instead of contacting the customer web server, we save money other than increasing the performance.
In the beginning, we tried to use cache systems like the Nginx cache, Varnish, or the AWS Cloudfront, but none of those met our customer requirements. For example:
- Get a list of cached contents and filter it by type (content-type) or size (content-length)
- Purge a single cached resource or a group of those
- Sync cached content from a region to other countries (or cluster nodes)
- Use stale cache if the upstream is not reachable
- Get stats and data about cache usage
- Compress plain text in cache such as CSS or JavaScript
- Optimize cached images
Moreover, the main requirement was having the cache centralized outside the single reverse proxy node, in order to scale in and out our cluster without loosing all cache element on a node. So, because of all these reasons, we decided to create our own cache system using Redis.
What is Redis?
Redis is an open-source, in-memory data structure store that can be used as a database, cache, and message broker. It’s designed to be fast and efficient, with a simple key-value data model that supports a wide range of data structures, including strings, hashes, lists, sets, and sorted sets.
One of the key benefits of Redis is its speed – since it stores data in memory, it can provide extremely low latency and high throughput. Additionally, Redis supports advanced features such as transactions, pub/sub messaging, Lua scripting, and more.
Redis is used by many popular applications and services, including Twitter, GitHub, and StackOverflow. Whether you’re building a small-scale application or a large-scale distributed system, Redis is a powerful tool that can help you optimize performance and scalability.
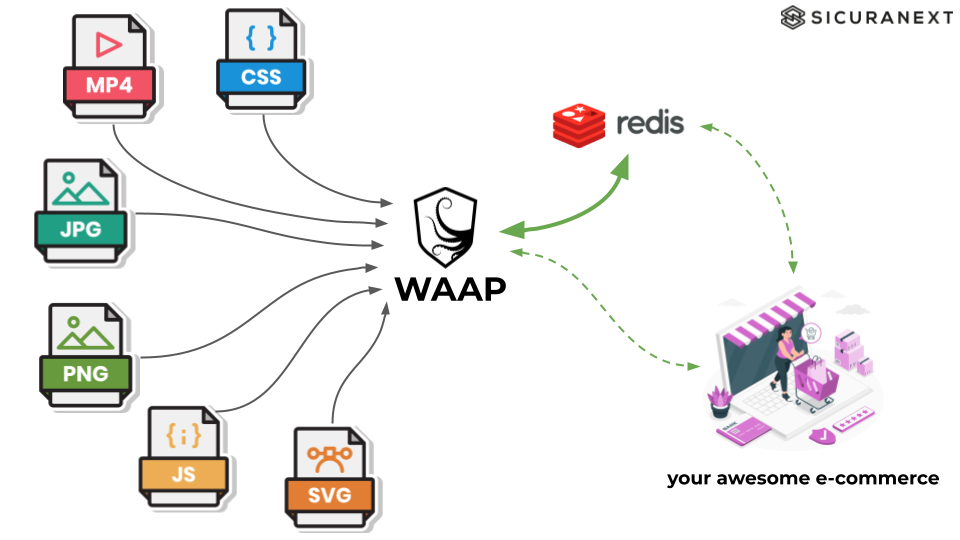
Now we have Redis, but where to start but where to start to create a cache proxy? We started from defining Cache Key.
Cache Key and Query String Normalization
When a proxy cache receives an HTTP request, it needs to determine if it has a cached version of the requested resource. To do this, all cache systems uses a “cache key”, which is a unique identifier for the requested resource. Typically, the cache key is generated by hashing part of the request, such as the URL or a subset of the request headers.
For example, a cache key could be generated by hashing the following information:
- scheme (http:// or https://)
- request method (GET, POST, etc..)
- request URI (/index.php)
- query string (news_id=1&cat=sport)
- request header host (example.com)
- request header accept-encoding (gzip)
- request header Vary? Let’s talk about it later…
This is just an example and doesn’t reflect how we create our own cache key hash. But it’s quite similar to the following:
echo "https"\
"example.com"\
"GET"\
"/style.css"\
"ver=2&async=true"\
"gzip, deflate, br"\
| md5sum
5a8e59e438c871339558bc799704f2b3Via the cache key hash, a proxy cache can quickly identify if it has a cached version of the requested resource. If the cache key matches an existing cached response, the cache can serve the response directly without contacting the origin server, which can significantly improve performance and reduce network traffic.
However, one challenge with caching is that URLs may contain query string parameters, which can have a significant impact on the resource being requested. To increase the cache hit ratio, proxy caches often normalize and sort the query string parameters and values in the URL.
The process of normalizing and sorting query string parameters typically involves the following steps:
- Sort all parameters and their values alphabetically by parameter name.
- Combine the sorted parameter names and values into a new query string.
- Optionally lowercase parameter names or parameter values.
For example, consider the following two URLs:
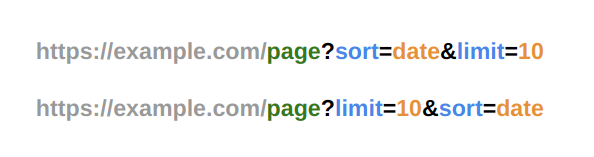
These URLs refer to the same resource, but the order of the query string parameters is different. In our example, without normalization, these two URLs will have two different cache key hash:
echo "httpsexample.com/pagesort=date&limit=10" | md5sum
deb77b2c11c932c77257df7916207e7e -
echo "httpsexample.com/pagelimit=10&sort=date" | md5sum
bb3fe19aaef5210b83d8eb14b84fb83c -By normalizing and sorting the parameters, the proxy cache can treat them as the same URL and increase the cache hit ratio. A high hit ratio is vital for a cache proxy because it means that more requests can be served from the cache instead of being forwarded to the origin server. This can improve performance and reduce network traffic. In addition, caching can reduce the load on the origin server, which can result in cost savings and increased scalability.
Accept-Encoding & Normalizzation
Including the accept-encoding request header in the cache key hash, is important if you want to respect the user’s required content encoding. This means that if a user requests a CSS without sending the accept-encoding header or sending it with the “identity” value, your webserver should send the plain version of the CSS content (not compressed/encoded).
As usual, the two main reasons to prefer sending a compressed response body instead of a plain version is to lower the response latency (that means increase performance by sending a smaller content to the browser) and lowering the paid outgoing traffic (saving money).
What is Accept-Encoding request header?
The Accept-Encoding request HTTP header indicates the content encoding (usually a compression algorithm) that the client can understand. The server uses content negotiation to select one of the proposals and informs the client of that choice with the Content-Encoding response header.
Even if both the client and the server support the same compression algorithms, the server may choose not to compress the body of a response if the identity value is also acceptable. Two common cases lead to this:
The data to be sent is already compressed, therefore a second compression will not reduce the transmitted data size. This is true for pre-compressed image formats (JPEG, for instance);
The server is overloaded and cannot allocate computing resources to perform the compression. For example, Microsoft recommends not to compress if a server uses more than 80% of its computational power.
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Accept-Encoding
Let normalize it!
As we did for the query string, the accept-encoding request header must be normalized and sorted to maximize the hit ratio. As you can see below, these are the top 10 Accept-Encoding request header values that we see on our customer’s websites. Every browser sends this value as they like, without ordering or normalizing it:
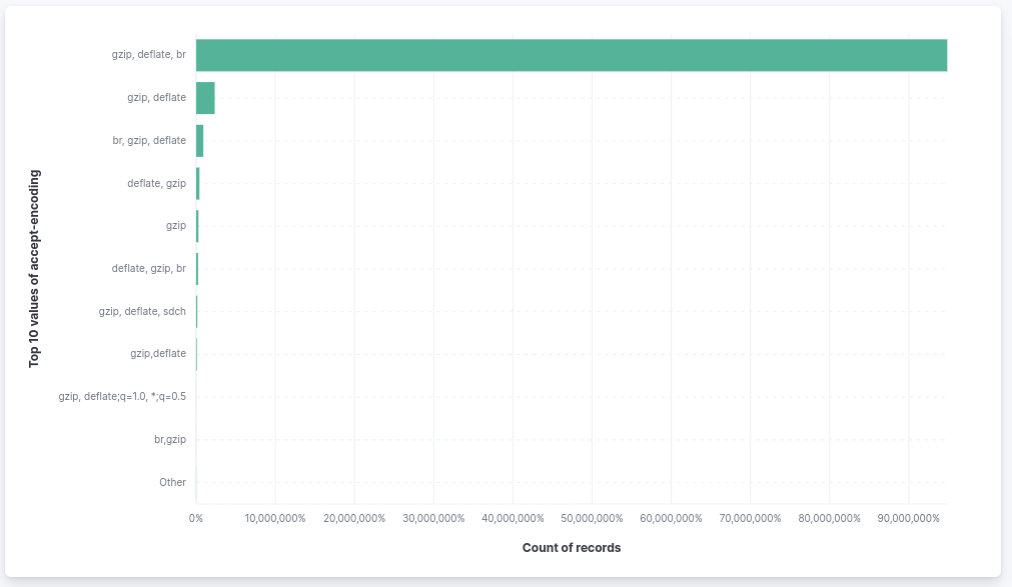
As you can see, the most used are “gzip, deflate, be”, followed by “gzip, deflate” and “br, gzip, deflate”. We can say that the following three HTTP requests refer to the same resource but with 3 different cache key hash:
# cache key 1
GET /style.css HTTP/1.1
Host: example.com
Accept-Encoding: gzip, deflate, br
# cache key 2
GET /style.css HTTP/1.1
Host: example.com
Accept-Encoding: gzip, deflate
# cache key 3
GET /style.css HTTP/1.1
Host: example.com
Accept-Encoding: br, gzip, deflateTo increase the hit ratio and makes these three requests hit the same cached content, we need to sort the accept-encoding values before hashing the cache key. For example: placing gzip always at first place, deflate always at second place, and br at third.
Isn’t it easy? No. Dealing with encoded/compressed contents is a mess. There’re tons of exceptions and many applications misuse the content-encoding response header that, many times, doesn’t respect the real response body encoding. For example:
- Sometimes webservers choose to not compress a content due to high CPU usage. So a compressed response can be sent uncompressed after revalidation.
- Some application doesn’t set the content-encoding even if the response has been gziped.
- Sometimes happens that a response has the content-encoding header set to gzip but the body is not compressed (many times due to intermediary that uncompress the body, for some reason, but doesn’t unset the content-encoding header).
Thankfully, browsers are not so fastidious and they render content even if content-encoding say gzip but the response body is not compressed.
Cache-Control: Do not cache private user content
To quote a well-known novel by Chuck Palahniuk:
The first rule of a proxy cache is “do not cache private content”. The second rule of a proxy cache is “DO NOT cache private content!”.
The Cache-Control HTTP header field holds directives (instructions) — in both requests and responses — that control caching in browsers and shared caches (e.g. Proxies, CDNs). It indicates whether a response can be stored in cache and if so, for how long and the conditions under which the response can be used from the cache.We choose to avoid caching response when the response header Cache-Control contains the following directives:
- private
- no-store
- max-age=0
Cache-Control: private The private response directive indicates that the response message is intended for a single user and MUST NOT be stored by a shared cache. A private cache MAY store the response and reuse it for later requests, even if the response would normally be non-cacheable.
Cache-Control: no-store The no-store response directive indicates that any caches of any kind (private or shared) should not store this response. So, the response is always fetched from the origin server, even if a copy of the same has been stored in the cache previously.
Cache-Control: max-age=0 The max-age response directive indicates that the response is to be considered stale after its age is greater than the specified number of seconds. A response that has exceeded its expiration time is normally not used to satisfy subsequent requests without first revalidating it with the origin server. However, if the max-age response directive is specified, then the response is to be considered stale after its age is greater than the specified number of seconds. If max-age is zero, then the client needs to revalidate the response with the origin server before using it for subsequent requests.
You may think that no-cache means “do not put this response in cache”, but it actually means “you can cache this response, but you must validate it with the server before using it again”. This is a subtle difference, but it’s important to understand.
Follow Vary header, but do not follow Vary header.
The Vary HTTP response header determines how to match future request headers to decide whether a cached response can be used rather than requesting a fresh one from the origin server. It is used by the server to indicate which headers it used when selecting a representation of a resource in a content negotiation algorithm.
In short, the Vary header is used to tell the browser that the response is different based on the value of the header specified in the Vary header. For example, if the Vary header is set to Accept-Encoding, it means that the response is different based on the Accept-Encoding header. So, if the browser sends a request with Accept-Encoding: gzip, the response will be different than if the browser sends a request with Accept-Encoding: br.
This is common with user-agent to serve different content based on the device used. For example, serving a mobile version of the website to mobile devices and a desktop version to desktop devices.
It is a good idea to include Vary in the cache-key but, based on our experience, it requires a lot of normalization. For example:
“Vary: user-agent” makes sense for the webserver, but if your goal is caching and keep a high cache hit ratio, it’s a really bad idea to include the user-agent as is in your cache-key hash. Consider the following list of User-Agent:
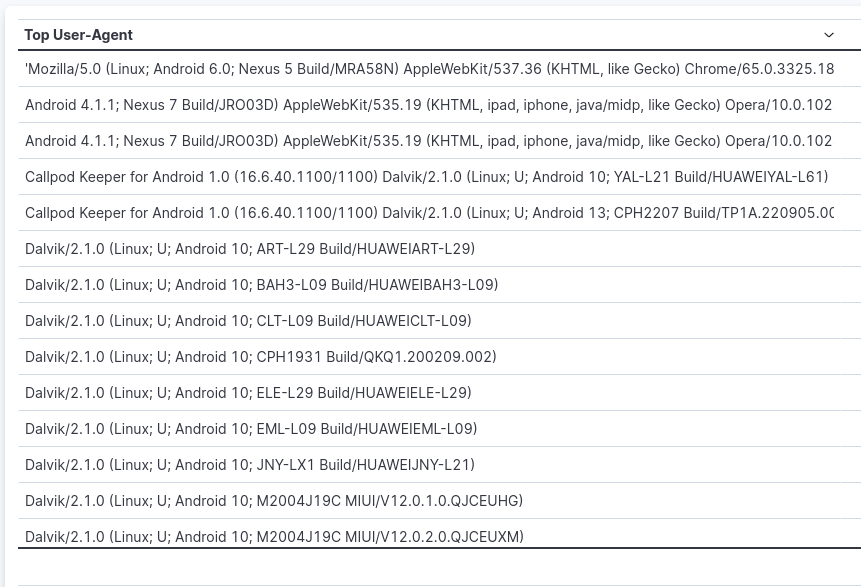
In the list above, there’re only mobile user-agent. As you can see there’re many different user-agent that basically will receive always the same content if “Vary: user-agent” response header is sent. Creating a cache-key for each user-agent would results in a low cache hit ratio. for that reason we started to “normalize” the user-agent if “Vary: user-agent” is present in the response.
The following example, is quite similar to the normalization we do using the Nginx Lua module. As you can see, we try to match mobile vendors/products in the user-agent that refer to a mobile device. If matches, we just insert “mobile” in the cache key avoiding using the whole user-agent value. If doesn’t matches, we just insert “desktop” in cache-key.
if ngx.re.match(user_agent, ".*(Mobile|Android|iPhone|iPad).*") then
cache_key_string = "vary-user-agent:mobile..."
else
cache_key_string = "vary-user-agent:desktop..."
endEviction and Object Count Limit
As we said earlier, Redis is an in-memory database, meaning that data is stored in memory rather than on disk. While this approach provides advantages in terms of speed and latency, it also presents limitations in terms of the amount of data that can be stored, as the available memory is usually limited and not so wide than a physical disk.
If your proxy cache automatically save static content type response (such as CSS, JavaScript, Fonts, Images, etc…), you’ll face the memory limit problem soon or later. To overcome this issue, Redis uses an eviction mechanism that automatically removes less frequently used data to make space for new data. When a certain memory limit is reached, Redis removes data according to a configured eviction policy.
There are several eviction policies available in Redis, including Least Recently Used (LRU), Least Frequently Used (LFU), and Random. The default eviction policy in Redis is LRU, but a different policy can be configured using the CONFIG SET maxmemory-policy command.
Using an LFU eviction policy in this case allows only the most frequently used data to be kept in memory, improving access speed to the most important data. However, it’s important to choose the eviction policy based on the specific needs of the application, as different policies may be more appropriate in different situations.
Another mandatory feature is to set an object count limit that a service can save in cache. It happens that some application insert random number or unix time epoch inside querystring parameter value. This leads to a lot of different cache keys for the same resource. For example:
- /images/product_a.png?ts=1682804398
- /images/product_a.png?ts=1682804412
- /images/product_a.png?ts=1682804424
- etc…
As you can imagine, this would lead to fill all the free memory really fast. For that reason, Octofence WAAP service limits the number of objects that a service can save to cache to 50.000 objects. This limit in conjunction with the Redis eviction guarantees that all protected websites can benefit from the cache without filling the memory up.
Thanks to years of experience, utilizing the CDN provided by our Octofence WAAP service, you can maximize the performance of your website by making it up to 10 times faster, while also saving on traffic and web server scaling. With Octofence WAAP, you can ensure that your website delivers the best user experience possible, while also optimizing your resources and reducing costs (other than protecting from attacks).